Toward an artificial intelligence physicist for unsupervised learning
Tailin Wu,Max Tegmark +1 more
TL;DR: In this paper, the authors propose a generalized mean loss to encourage each theory to specialize in its comparatively advantageous domain, and a differentiable description length objective to downweight bad data and "snap" learned theories into simple symbolic formulas.
read more
Abstract: We investigate opportunities and challenges for improving unsupervised machine learning using four common strategies with a long history in physics: divide and conquer, Occam's razor, unification, and lifelong learning. Instead of using one model to learn everything, we propose a paradigm centered around the learning and manipulation of theories, which parsimoniously predict both aspects of the future (from past observations) and the domain in which these predictions are accurate. Specifically, we propose a generalized mean loss to encourage each theory to specialize in its comparatively advantageous domain, and a differentiable description length objective to downweight bad data and "snap" learned theories into simple symbolic formulas. Theories are stored in a "theory hub," which continuously unifies learned theories and can propose theories when encountering new environments. We test our implementation, the toy "artificial intelligence physicist" learning agent, on a suite of increasingly complex physics environments. From unsupervised observation of trajectories through worlds involving random combinations of gravity, electromagnetism, harmonic motion, and elastic bounces, our agent typically learns faster and produces mean-squared prediction errors about a billion times smaller than a standard feedforward neural net of comparable complexity, typically recovering integer and rational theory parameters exactly. Our agent successfully identifies domains with different laws of motion also for a nonlinear chaotic double pendulum in a piecewise constant force field.
read more
Chat with Paper
AI Agents for this Paper
Find similar papers on Google Scholar, PubMed and Arxiv
Write a critical review of this paper
Analyze citations of this paper to find unaddressed research gaps
Figures

TABLE I: AI Physicist strategies tested. 
FIG. 4: In this sample mystery world, a ball moves through a harmonic potential (upper left quadrant), a gravitational field (lower left) and an electromagnetic field (lower right quadrant) and bounces elastically from four walls. The only input to the AI Physicist is the sequence of dots (ball positions); the challenge is to learn all boundaries and laws of motion (predicting each position from the previous two). The color of each dot represents the domain into which it is classified by c, and its area represents the description length of the error with which its position is predicted ( = 10−6) after the DDAC (differentiable divide-and-conquer) algorithm; the AI Physicist tries to minimize the total area of all dots. 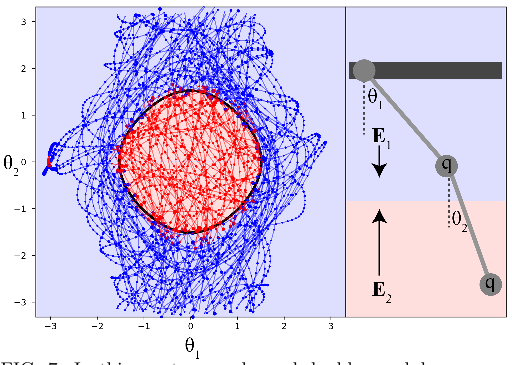
FIG. 7: In this mystery, a charged double pendulum moves through two different electric fields E1 and E2, with a domain boundary corresponding to cos θ1 + cos θ2 = 1.05 (the black curve above left, where the lower charge crosses the Efield boundary). The color of each dot represents the domain into which it is classified by a Newborn agent, and its area represents the description length of the error with which its position is predicted, for a precision floor ≈ 0.006. In this world, the Newborn agent has a domain prediction accuracy of 96.5%. 
FIG. 6: Example of automatically determined boundary points, for region boundary points (green), bounce boundary points (black) and failed cases (red). 
FIG. 5: Points where forward and backward extrapolations agree (large black dots) are boundary points. The tangent vectors agree for region boundaries (upper example), but not for bounce boundaries (lower example). 
FIG. 2: The description length DL is shown for real numbers p with = 2−14 (rising curve) and for rational numbers (dots). Occam’s Razor favors lower DL, and our MDL rational approximation of a real parameter p is the lowest point after taking these “model bits” specifying the approximate parameter and adding the “data bits” L required to specify the prediction error made. The two symmetric curves illustrate the simple example where L = log+ ( x−x0 ) for x0 = 1.4995, = 2−14 and 0.02, respectively.






Citations
•Posted Content
Learning without Forgetting
Zhizhong Li,Derek Hoiem +1 more
TL;DR: This work proposes the Learning without Forgetting method, which uses only new task data to train the network while preserving the original capabilities, and performs favorably compared to commonly used feature extraction and fine-tuning adaption techniques.
2.6K
AI Feynman: A physics-inspired method for symbolic regression
TL;DR: This work develops a recursive multidimensional symbolic regression algorithm that combines neural network fitting with a suite of physics-inspired techniques and improves the state-of-the-art success rate.
944
Discovering Physical Concepts with Neural Networks
TL;DR: In this article, a neural network architecture based on the human physical reasoning process is proposed for scientific discovery from experimental data without making prior assumptions about the system, which can help to gain conceptual insights.
475
•Journal Article
Learning phase transitions by confusion
TL;DR: This work proposes a neural-network approach to finding phase transitions, based on the performance of a neural network after it is trained with data that are deliberately labelled incorrectly, and paves the way to the development of a generic tool for identifying unexplored phase transitions.
Social physics
TL;DR: The field of social physics has been a hot topic in the last few decades as mentioned in this paper , with many researchers venturing outside of their traditional domains of interest, but also taking from physics the methods that have proven so successful throughout the 19th and the 20th century.
References
Deep learning
TL;DR: Deep learning is making major advances in solving problems that have resisted the best attempts of the artificial intelligence community for many years, and will have many more successes in the near future because it requires very little engineering by hand and can easily take advantage of increases in the amount of available computation and data.
67K
I and i
TL;DR: There is, I think, something ethereal about i —the square root of minus one, which seems an odd beast at that time—an intruder hovering on the edge of reality.
38.1K
A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting
Yoav Freund,Robert E. Schapire +1 more
- 01 Aug 1997
TL;DR: The model studied can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting, and it is shown that the multiplicative weight-update Littlestone?Warmuth rule can be adapted to this model, yielding bounds that are slightly weaker in some cases, but applicable to a considerably more general class of learning problems.
Introduction to algorithms: 4. Turtle graphics
TL;DR: In this article, a language similar to logo is used to draw geometric pictures using this language and programs are developed to draw geometrical pictures using it, which is similar to the one we use in this paper.
15.4K