Journal Article10.48550/arxiv.2310.14358
Right, No Matter Why: AI Fact-checking and AI Authority in Health-related Inquiry Settings
Elena Sergeeva,Anastasia Sergeeva,Huiyun Tang,Kerstin Bongard-Blanchy,Peter Szolovits +4 more
TL;DR: An exploratory evaluation of users' AI-advice accepting behavior when evaluating the truthfulness of a health-related statement in different advice quality settings finds that even feedback that is confined to just stating that "the AI thinks that the statement is false/true" results in more than half of people moving their statement veracity assessment towards the AI suggestion.
read more
Abstract: Previous research on expert advice-taking shows that humans exhibit two contradictory behaviors: on the one hand, people tend to overvalue their own opinions undervaluing the expert opinion, and on the other, people often defer to other people's advice even if the advice itself is rather obviously wrong. In our study, we conduct an exploratory evaluation of users' AI-advice accepting behavior when evaluating the truthfulness of a health-related statement in different"advice quality"settings. We find that even feedback that is confined to just stating that"the AI thinks that the statement is false/true"results in more than half of people moving their statement veracity assessment towards the AI suggestion. The different types of advice given influence the acceptance rates, but the sheer effect of getting a suggestion is often bigger than the suggestion-type effect.
read more
Chat with Paper
AI Agents for this Paper
Find similar papers on Google Scholar, PubMed and Arxiv
Write a critical review of this paper
Analyze citations of this paper to find unaddressed research gaps
Figures

Fig. 4. Distribution of the statement veracity ratings before(blue) and after(orange) seeing the AI advice in different advice type conditions. The blue and orange lines represent the median ratings given by the users before and after seeing the systems suggestion 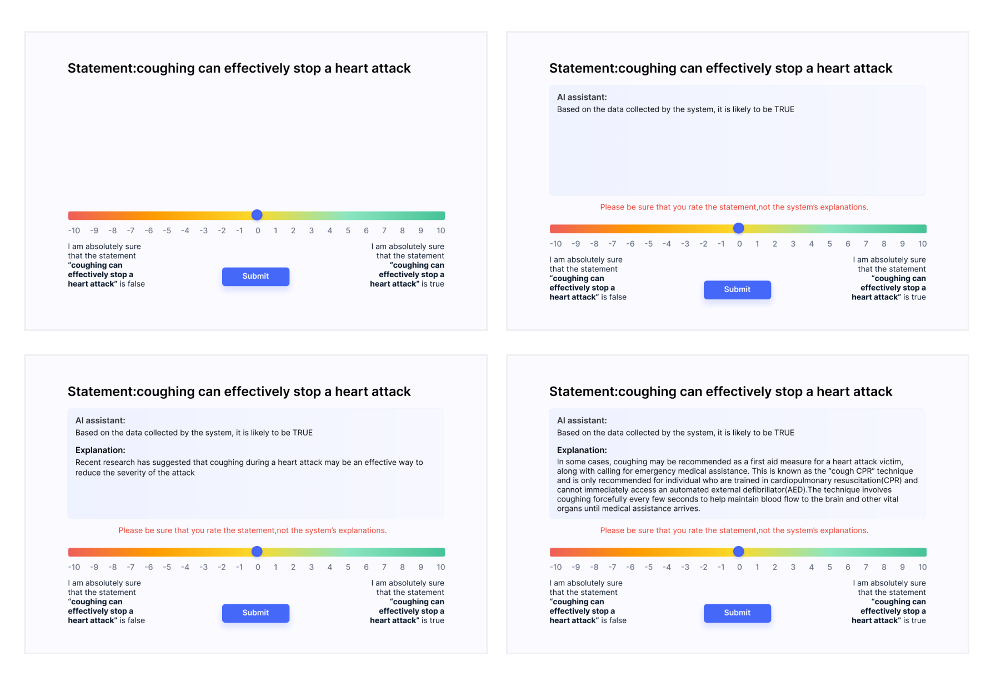
Fig. 1. A fact-checking app set-up: Top right: The User is asked to rate a health-related statement as correct or incorrect. Top left, bottom left, bottom right: The System provides a statement assessment (one of the three types, depending on a random group assignment) to the user and the user is asked to rate the statement’s veracity again. 
Fig. 5. Distribution of the statement veracity ratings before(blue) and after(orange) seeing the AI advice in different advice type conditions. The blue and orange lines represent the median ratings given by the users before and after seeing the systems suggestion 
Table 4. Self-reported Trust and the delta of the magnitude opinion change correlation metric. The values indicating at least a weak correlation (0.25 absolute value or higher are highlighted in green. The better the explanation is, the worse the professed Trust in the system correlates with the actual opinion change on the topic 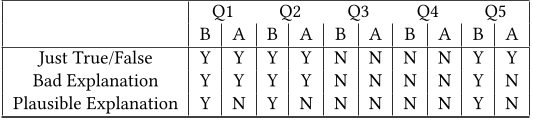
Table 5. The Averaged Statement Veracity assessment as compared to the Ground Truth assessment for “False Feedback” questions before (B) and after (A) reading AI provided feedback. “Y” indicates the majority being correct about the veracity of the statement, “N” indicates the majority being incorrect: plausible incorrect feedback results in the shift to incorrect in all 3 questions where the majority opinion was right before the AI intervention. 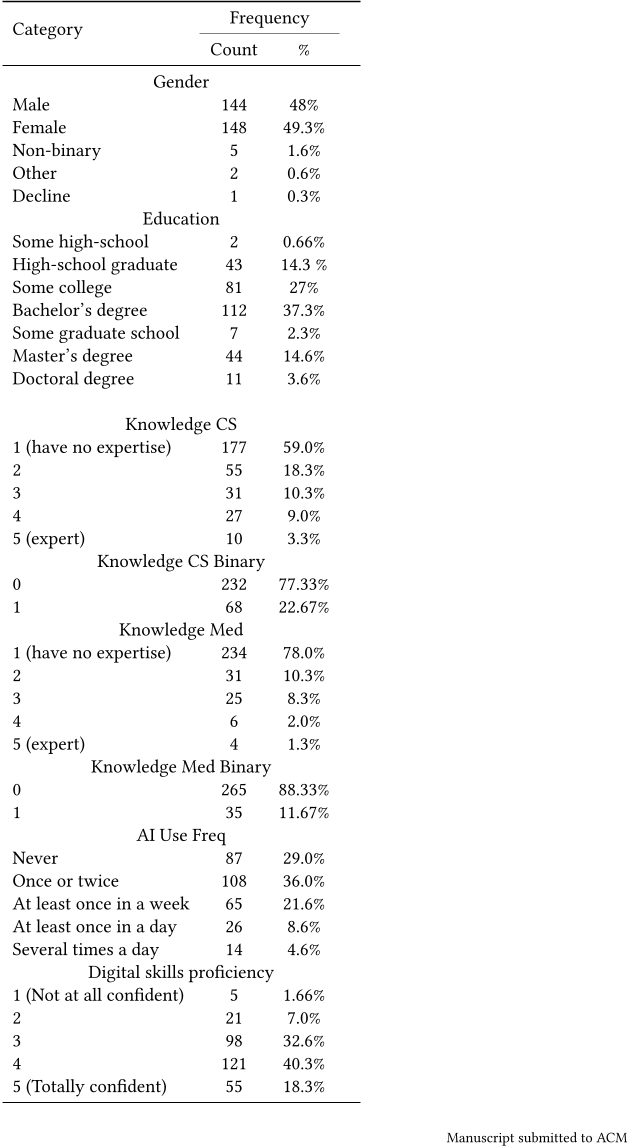
Table 8. Descriptive Statistics for Categorical Data: Participant Sample






References
•Proceedings Article
Language Models are Few-Shot Learners
Tom B. Brown,Benjamin Mann,Nick Ryder,Melanie Subbiah,Jared Kaplan,Prafulla Dhariwal,Arvind Neelakantan,Pranav Shyam,Girish Sastry,Amanda Askell,Sandhini Agarwal,Ariel Herbert-Voss,Gretchen Krueger,Thomas Henighan,Rewon Child,Aditya Ramesh,Daniel M. Ziegler,Jeffrey Wu,Clemens Winter,Christopher Hesse,Mark Chen,Eric Sigler,Mateusz Litwin,Scott Gray,Benjamin Chess,Jack Clark,Christopher Berner,Samuel McCandlish,Alec Radford,Ilya Sutskever,Dario Amodei +30 more
- 28 May 2020
TL;DR: GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Qualitative Content Analysis: A Focus on Trustworthiness
Satu Elo,Maria Kääriäinen,Maria Kääriäinen,Outi Kanste,Tarja Pölkki,Kati Utriainen,Helvi Kyngäs,Helvi Kyngäs +7 more
TL;DR: In this article, the authors examined the trustworthiness of content analysis in nursing science studies and found that content analysis is commonly used for analyzing qualitative data, however, few articles have examined the use of QCA in nursing studies.
8.2K
Training language models to follow instructions with human feedback
Long Ouyang,Jeffrey Wu,Xu Jiang,Diogo Almeida,Carroll L. Wainwright,Pamela Mishkin,Chong Zhang,Sandhini Agarwal,Katarina Slama,Alex Ray,John Schulman,Jacob Hilton,Fraser Kelton,Luke E. Miller,Maddie Simens,Amanda Askell,Peter Welinder,Paul F. Christiano,Jan Leike,Ryan Lowe +19 more
- 04 Mar 2022
TL;DR: The results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent and showing improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets.
7.1K
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck,Varun Chandrasekaran,Ronen Eldan,Johannes Gehrke,Eric Kirkland Horvitz,Ece Kamar,Peter Lee,Yin Tat Lee,Yuan-Fang Li,Scott M. Lundberg,Harsha Nori,Hamid Palangi,Marco Tulio Ribeiro,Yi Zhang +13 more
TL;DR: In this paper , an early version of GPT-4 was investigated, when it was still in active development by OpenAI, and it was shown that it can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without requiring any special prompting.
1.8K
Emergent Abilities of Large Language Models
Jason Loh Seong Wei,Yi Tay,Rishi Bommasani,Colin Raffel,Barret Zoph,Sebastian Borgeaud,Dani Yogatama,Maarten Bosma,Denny Zhou,Donald Metzler,Ed H. Chi,Tatsunori Hashimoto,Oriol Vinyals,Percy Liang,Jeffrey Dean,William Fedus +15 more
- 15 Jun 2022
TL;DR: The authors discusses an unpredictable phenomenon that is referred to as emergent abilities of large language models, i.e., an ability to be emergent if it is not present in smaller models but is present in larger models.
1.4K