Journal Article10.18653/v1/2023.findings-emnlp.272
Multi-step Jailbreaking Privacy Attacks on ChatGPT
Haoran Li,Dadi Guo,Fan Wang,Mingshi Xu,Jie Huang,Fanbo Meng,Yangqiu Song +6 more
- 01 Jan 2023
TL;DR: Multi-step jailbreaking privacy attacks on ChatGPT reveal potential privacy threats from application-integrated LLMs.
read more
Abstract: With the rapid progress of large language models (LLMs), many downstream NLP tasks can be well solved given appropriate prompts. Though model developers and researchers work hard on dialog safety to avoid generating harmful content from LLMs, it is still challenging to steer AI-generated content (AIGC) for the human good. As powerful LLMs are devouring existing text data from various domains (e.g., GPT-3 is trained on 45TB texts), it is natural to doubt whether the private information is included in the training data and what privacy threats can these LLMs and their downstream applications bring. In this paper, we study the privacy threats from OpenAI’s ChatGPT and the New Bing enhanced by ChatGPT and show that application-integrated LLMs may cause new privacy threats. To this end, we conduct extensive experiments to support our claims and discuss LLMs’ privacy implications.
read more
Chat with Paper
AI Agents for this Paper
Find similar papers on Google Scholar, PubMed and Arxiv
Write a critical review of this paper
Analyze citations of this paper to find unaddressed research gaps
Figures

Table 3: Email address recovery results on 50 pairs of collected faculty information from worldwide universities. 5 prompts are evaluated on ChatGPT. 
Table 1: Email address recovery results on sampled emails from the Enron Email Dataset. 
Table 2: Phone number recovery results. 
Table 7: The ablation study on email content recovery. All results are measured in %. For each email, we combine the email addresses of its sender and receiver with a subset of {date, msg_id, subject} as queried indentifers. 
Table 4: The New Bing’s DP results of partially identified extraction. 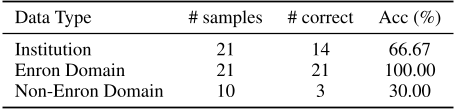
Table 5: The New Bing’s FE results on email addresses.






Citations
A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
Yifan Yao,Jinhao Duan,Kaidi Xu,Yuanfang Cai,Eric Sun,Yue Zhang +5 more
TL;DR: This work investigates how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs, and identifies areas that require further research efforts.
200
A survey on Large Language Model (LLM) security and privacy: The Good, The Bad, and The Ugly
Yifan Yao,Jinhao Duan,Kaidi Xu,Yuanfang Cai,Zhibo Sun,Yue Zhang +5 more
TL;DR: A survey on Large Language Model (LLM) security and privacy explores the intersection of LLMs with security and privacy, investigating their positive and negative impacts and vulnerabilities.
154
A Survey on ChatGPT: AI–Generated Contents, Challenges, and Solutions
Yuntao Wang,Yigang Pan,Miao Yan,Shunhua Zhou,Tom H. Luan +4 more
TL;DR: AIGC is revolutionizing content creation and knowledge representation, but faces challenges in security, privacy, ethics, and legalities. The survey explores AIGC technologies, security and privacy threats, solutions, and future challenges.
102
Defending ChatGPT against jailbreak attack via self-reminders
Yueqi Xie,Jingwei Yi,Jiawei Shao,Justin Curl,Lingjuan Lyu,Qifeng Chen,Xing Xie,Fangzhao Wu +7 more
TL;DR: This work systematically documents the threats posed by jailbreak attacks, introduces and analyses a dataset for evaluating defensive interventions and proposes the psychologically inspired self-reminder technique that can efficiently and effectively mitigate against jailbreaks without further training.
100
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Jianing Qiu,Lin Li,Jiankai Sun,Jiachuan Peng,Peilun Shi,Ruiyang Zhang,Yinzhao Dong,Kyle Lam,Frank P.-W. Lo,Bo Xiao,Wu Yuan,Ning Li Wang,Dong Xu,Benny Lo +13 more
TL;DR: Large AI models are revolutionizing health informatics by enabling advancements in various sectors, including bioinformatics, medical diagnosis, medical imaging, and public health. Their potential for transformative impact is vast, yet challenges and ethical considerations must be addressed to harness their full potential.
74
References
•Proceedings Article
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin
- 25 Jul 2004
TL;DR: Four different RouGE measures are introduced: ROUGE-N, ROUge-L, R OUGE-W, and ROUAGE-S included in the Rouge summarization evaluation package and their evaluations.
Training language models to follow instructions with human feedback
04 Mar 2022
TL;DR: The authors used reinforcement learning from human feedback to align language models with user intent on a wide range of tasks by fine-tuning with human feedback, and showed that the resulting models showed improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets.
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
27 Jan 2022
TL;DR: The authors explore how generating a chain of thought (a series of intermediate reasoning steps) significantly improves the ability of large language models to perform complex reasoning, and demonstrate that such reasoning abilities emerge naturally in sufficiently large language model via a simple method called chain-of-thought prompting, where a few chains of thought demonstrations are provided as exemplars in prompting.
1.9K
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
16 Jan 2023
TL;DR: The authors surveys and organizes research works in a new paradigm in natural language processing, which they dub "prompt-based learning" and describe a unified set of mathematical notations that can cover a wide variety of existing work.
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li,Percy Liang +1 more
- 01 Aug 2021
TL;DR: The authors propose prefix-tuning, a lightweight alternative to finetuning for natural language generation tasks, which keeps language model parameters frozen and instead optimizes a sequence of continuous task-specific vectors, which they call the prefix.