Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes.
Rachel Lea Draelos,David Dov,Maciej A. Mazurowski,Joseph Y. Lo,Ricardo Henao,Geoffrey D. Rubin,Lawrence Carin +6 more
TL;DR: In this paper, a rule-based method was developed for automatically extracting abnormality labels from free-text radiology reports with an average F-score of 0.976 (min 0.541, max 1.0).
read more
About: This article is published in Medical Image Analysis. The article was published on 01 Jan 2021. and is currently open access.
read more
Chat with Paper
AI Agents for this Paper
Find similar papers on Google Scholar, PubMed and Arxiv
Write a critical review of this paper
Analyze citations of this paper to find unaddressed research gaps
Figures

Table 1. List of 83 Abnormalities that SARLE Extracts from Radiology Reports. Note that each abnormality is associated with a set of medical synonyms that are defined in a term search step. For example, the term search for cardiomegaly captures “cardiomegaly,” “dilated ventricles,” “enlarged right atrium,” and other synonyms. “Lung resection” captures pneumonectomy and lobectomy; “breast surgery” captures mastectomy and lumpectomy; pleural effusion captures “pleural effusion” and “pleural fluid” and so on. The term search for all abnormalities is available in Appendix B. 
Table 2. Examples of the term search used in our radiology label extraction framework, from simple (e.g., mass) to complex (e.g., cardiomegaly). The presence of any word in the “Any” column will result in considering the associated abnormality positive. The presence of any word in the “Term 1” column along with any word in the “Term 2” column will result in considering the associated abnormliaty positive. “Example Matches” shows example words and phrases that will result in a positive label for that abnormlaity based on the term search. Appendix B includes the full term search. 
Table 3: SARLE performance for the 427 chest CT test reports across the 9 labels with manually obtained ground truth. “# Pos” is the number of positive examples for that label in the report test set. F = equally weighted harmonic mean of precision and recall, P = Precision, R = Recall, Acc = Accuracy. 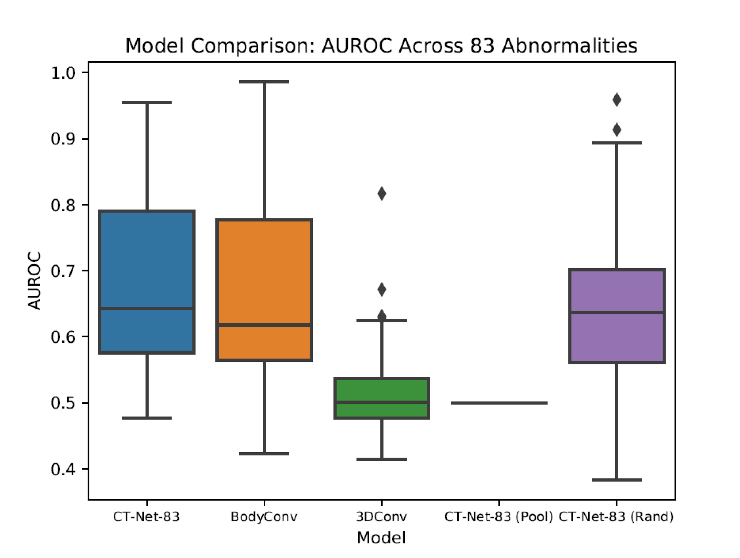
Figure 3. Architecture Comparison and Ablation Study on Training/Validation Data Subset. 
Table 5. CT-Net-83 test set AUROC and Average Precision for abnormalities with the highest and lowest AUROCs. Note that the baseline for average precision is equal to the frequency of the abnormality being considered; this frequency is provided in the Test Set Percent column. Thus, an average precision of 0.463 for honeycombing is high, given honeycombing’s baseline of only 0.027. 
Figure 1. Study Overview. (a) Reports from chest CT scans performed without intravenous contrast material were acquired from the Duke Enterprise Data Unified Content Explorer (DEDUCE) search tool as well as the Epic electronic health record (EHR). Report accession numbers were used to download CT slices as DICOMs from the Duke Image Archive (DIA), which were processed into a final data set of 36,316 CT volumes. (b) We develop an approach for extracting binary labels for 83 different abnormalities from the free-text chest CT reports. (c) We train and evaluate a deep convolutional neural network model (shown here and detailed further in Figure 2) that takes as input a whole CT volume and predicts all 83 abnormality labels simultaneously.






Citations
MIDCAN: A multiple input deep convolutional attention network for Covid-19 diagnosis based on chest CT and chest X-ray.
TL;DR: Wang et al. as discussed by the authors proposed an end-to-end multiple-input deep convolutional attention network (MIDCAN), which fused chest CT with chest X-ray to improve the AI's diagnosis performance.
106
Ontology-driven weak supervision for clinical entity classification in electronic health records.
Jason A. Fries,Ethan Steinberg,Saelig Khattar,Scott L. Fleming,Jose D. Posada,Alison Callahan,Nigam H. Shah +6 more
TL;DR: In this article, a framework for weakly supervised entity classification using medical ontologies and expert-generated rules is presented, unlike hand-labeled notes, is easy to share and modify, while offering performance comparable to learning from manually labeled training data.
Research on the Auxiliary Classification and Diagnosis of Lung Cancer Subtypes Based on Histopathological Images
Min Li,Xiaojian Ma,Chen Chen,Yushuai Yuan,Shuailei Zhang,Ziwei Yan,Cheng Chen,Fangfang Chen,Yujie Bai,Panyun Zhou,Xiaoyi Lv,Mingrui Ma +11 more
TL;DR: Wang et al. as mentioned in this paper proposed a computer-aided diagnosis method based on histopathological images of ASC, lung squamous cell carcinoma (LUSC) and small cell lung carcinoma(SCLC).
Federated Learning for Healthcare Applications
Ahmad Chaddad,Yihang Wu,Christian Desrosiers +2 more
TL;DR: This survey provides an introduction to the fundamental concepts and categories of FL, highlights the limitations of the centralized healthcare model, and discusses how FL can address these constraints.
27
Development and validation of an abnormality-derived deep-learning diagnostic system for major respiratory diseases
Chengdi Wang,Jiechao Ma,Shu Zhang,Jun Shao,Yanyan Wang,Hong-Yu Zhou,Lujia Song,Jie Zheng,Yizhou Yu,Weimin Li +9 more
TL;DR: DeepMRDTR as discussed by the authors is a deep learning-based medical image interpretation system for the diagnosis of major respiratory diseases based on the automated identification of a wide range of radiological abnormalities through computed tomography (CT) and chest X-ray (CXR) from real-world, large-scale datasets.
References
Deep Residual Learning for Image Recognition
Kaiming He,Xiangyu Zhang,Shaoqing Ren,Jian Sun +3 more
- 27 Jun 2016
TL;DR: In this article, the authors proposed a residual learning framework to ease the training of networks that are substantially deeper than those used previously, which won the 1st place on the ILSVRC 2015 classification task.
•Posted Content
Deep Residual Learning for Image Recognition
TL;DR: This work presents a residual learning framework to ease the training of networks that are substantially deeper than those used previously, and provides comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth.
117.9K
Controlling the false discovery rate: a practical and powerful approach to multiple testing
Yoav Benjamini,Yosef Hochberg +1 more
TL;DR: In this paper, a different approach to problems of multiple significance testing is presented, which calls for controlling the expected proportion of falsely rejected hypotheses -the false discovery rate, which is equivalent to the FWER when all hypotheses are true but is smaller otherwise.
•Proceedings Article
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan,Andrew Zisserman +1 more
- 04 Sep 2014
TL;DR: This work investigates the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting using an architecture with very small convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers.
102.6K
ImageNet classification with deep convolutional neural networks
TL;DR: A large, deep convolutional neural network was trained to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes and employed a recently developed regularization method called "dropout" that proved to be very effective.