Journal Article10.48550/arXiv.2307.03109
A Survey on Evaluation of Large Language Models
Yu-Chu Chang,Xu Wang,Jindong Wang,Yuanyi Wu,Hao Chen,Linyi Yang,Xiaoyuan Yi,Cunxiang Wang,Yidong Wang,Weirong Ye,Yue Zhang,Philip S. Yu,Qian Yang,Xingxu Xie +13 more
TL;DR: A comprehensive review of the evaluation methods for large language models can be found in this paper , where the authors provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, education, natural and social sciences, agent applications, and other areas.
read more
Abstract: Large language models (LLMs) are gaining increasing popularity in both academia and industry, owing to their unprecedented performance in various applications. As LLMs continue to play a vital role in both research and daily use, their evaluation becomes increasingly critical, not only at the task level, but also at the society level for better understanding of their potential risks. Over the past years, significant efforts have been made to examine LLMs from various perspectives. This paper presents a comprehensive review of these evaluation methods for LLMs, focusing on three key dimensions: what to evaluate, where to evaluate, and how to evaluate. Firstly, we provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, ethics, educations, natural and social sciences, agent applications, and other areas. Secondly, we answer the `where' and `how' questions by diving into the evaluation methods and benchmarks, which serve as crucial components in assessing performance of LLMs. Then, we summarize the success and failure cases of LLMs in different tasks. Finally, we shed light on several future challenges that lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to researchers in the realm of LLMs evaluation, thereby aiding the development of more proficient LLMs. Our key point is that evaluation should be treated as an essential discipline to better assist the development of LLMs. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/LLM-eval-survey.
read more
Chat with Paper
AI Agents for this Paper
Find similar papers on Google Scholar, PubMed and Arxiv
Write a critical review of this paper
Analyze citations of this paper to find unaddressed research gaps
Figures

Table 8. Summary of new LLMs evaluation protocols. 
Table 7. Summary of existing LLMs evaluation benchmarks (ordered by the name of the first author). 
Fig. 1. Structure of this paper. 
Table 5. Summary of evaluations on medical applications based on the three aspects: Medical queries, Medical assistants, and Medical examination (ordered by the name of the first author). 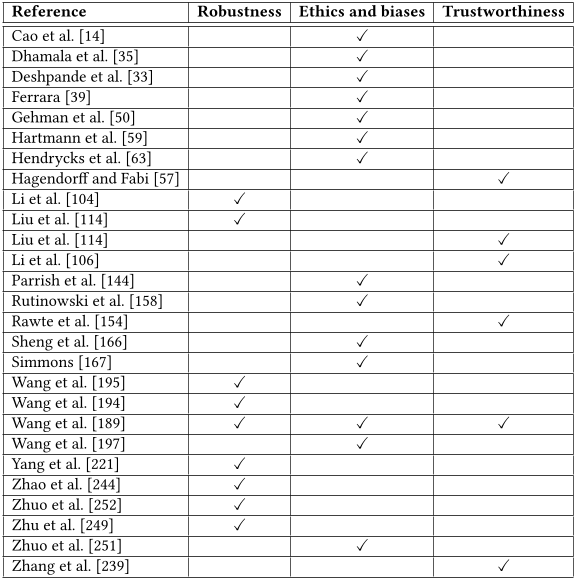
Table 3. Summary of LLMs evaluation on robustness, ethics, biases, and trustworthiness (ordered by the name of the first author). 
Table 2. Summary of evaluation on natural language processing tasks: NLU (Natural Language Understanding, including SA (Sentiment Analysis), TC (Text Classification), NLI (Natural Language Inference) and other NLU tasks), Reasoning, NLG (Natural Language Generation, including Summ. (Summarization), Dlg. (Dialogue), Tran (Translation), QA (Question Answering) and other NLG tasks), and Multilingual tasks (ordered by the name of the first author).






Citations
A Survey on Large Language Model based Autonomous Agents
Lei Wang,Cheng-jian Ma,Xueyang Feng,Zeyu Zhang,Hao-ran Yang,Jingsen Zhang,Zhi-Yang Chen,Jiakai Tang,Xu Chen,Yankai Lin,Wayne Xin Zhao,Zhewei Wei,Ji-Rong Wen +12 more
TL;DR: A systematic review of the field of LLM-based autonomous agents from a holistic perspective, and proposes a unified framework that encompasses a majority of the previous work.
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang,Yafu Li,Leyang Cui,Deng Li Cai,Lemao Liu,Tingchen Fu,Xinting Huang,Enbo Zhao,Yu Zhang,Yulong Chen,Longyue Wang,Anh Tuan Luu,Wei Bi,Freda Shi,Shuming Shi +14 more
TL;DR: This paper presents taxonomies of the LLM hallucination phenomena and evaluation benchmarks, analyzes existing approaches aiming at mitigating LLm hallucination, and discusses potential directions for future research.
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos,Ryan A. Rossi,Joe Barrow,Md. Mehrab Tanjim,Sungchul Kim,Franck Dernoncourt,Ruiyi Zhang,Nesreen K. Ahmed +7 more
TL;DR: This paper consolidates, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs, and proposes three intuitive taxonomies, two for bias evaluation and datasets, and one for mitigation.
A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
Yifan Yao,Jinhao Duan,Kaidi Xu,Yuanfang Cai,Eric Sun,Yue Zhang +5 more
TL;DR: This work investigates how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs, and identifies areas that require further research efforts.
200
Large Language Models: A Survey
Shervin Minaee,Tomas Mikolov,Narjes Nikzad,M. Chenaghlu,Richard Socher,Xavier Amatriain,Jianfeng Gao +6 more
TL;DR: This paper reviews some of the most prominent LLMs, including three popular LLM families (GPT, LLaMA, PaLM), and discusses their characteristics, contributions and limitations, and gives an overview of techniques developed to build, and augment LLMs.
194
References
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang,Yafu Li,Leyang Cui,Deng Li Cai,Lemao Liu,Tingchen Fu,Xinting Huang,Enbo Zhao,Yu Zhang,Yulong Chen,Longyue Wang,Anh Tuan Luu,Wei Bi,Freda Shi,Shuming Shi +14 more
TL;DR: This paper presents taxonomies of the LLM hallucination phenomena and evaluation benchmarks, analyzes existing approaches aiming at mitigating LLm hallucination, and discusses potential directions for future research.
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
TL;DR: EvalPlus as mentioned in this paper augments a given evaluation dataset with large amounts of test-cases newly produced by an automatic test input generator, powered by both LLM-and mutation-based strategies.
Dynabench: Rethinking Benchmarking in NLP.
Douwe Kiela,Max Bartolo,Yixin Nie,Divyansh Kaushik,Atticus Geiger,Zhengxuan Wu,Bertie Vidgen,Grusha Prasad,Amanpreet Singh,Pratik Ringshia,Zhiyi Ma,Tristan Thrush,Sebastian Riedel,Zeerak Waseem,Pontus Stenetorp,Robin Jia,Mohit Bansal,Christopher Potts,Adina Williams +18 more
- 01 Jun 2021
TL;DR: It is argued that Dynabench addresses a critical need in the community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin,Shi Liang,Yining Ye,Kunlun Zhu,Lan Yan,Ya-Ting Lu,Yankai Lin,Xin Cong,Xiangru Tang,Bill Qian,Sihan Zhao,Runchu Tian,Ruobing Xie,Jie Zhou,Marc Gerstein,Dahai Li,Zhiyuan Liu,Maosong Sun +17 more
TL;DR: ToolLLM is introduced, a general tool-use framework encompassing data construction, model training, and evaluation, and a novel depth-first search-based decision tree algorithm that enables LLMs to evaluate multiple reasoning traces and expand the search space.
Language Is Not All You Need: Aligning Perception with Language Models
Shaohan Huang,Li Dong,Wenhui Wang,Yaru Hao,Saksham Singhal,Shuming Ma,Tengchao Lv,Lei Cui,Owais Mohammed,Qiang Liu,Kriti Aggarwal,Zewen Chi,Johan Bjorck,Vishrav Chaudhary,Subhojit Som,Xia Song,F. Zhang Wei +16 more
TL;DR: This paper proposed a multimodal large language model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (e.g., zero-shot).